

Navigating the Depths: A Comprehensive Guide to AWS Data Lakes
In the ever-changing realm of data management, organizations are increasingly diving into data lakes to store, manage, and analyze extensive and varied datasets. The aim of this blogpost is to delve into the context of data lakes in the cloud, spotlighting on Amazon Web Services (AWS). It will explore the data lake concept in the cloud, examining key services and components involved in a modern data lake house strategy.
Comprehending Data Lakes in the cloud
Given the rapid growth of data due to evolving technologies and industry demands, traditional on-premises architectures struggle to cope with the escalating volumes. In the past, data was confined to silos, hindering seamless data sharing among diverse consumers. Silo-based architectures, initially designed for small applications managed by single teams, evolved into fragmented systems as different groups developed more applications. As data became increasingly relevant across organizations, the transition to a modern data lake architecture became imperative. This modern approach facilitates swift and straightforward democratization of value extraction from all data, breaking down data segregation and empowering decision-makers.
A modern data architecture empowers customers to adopt data analytics principles. It involves extracting maximum value, reducing latency, and generating actionable insights. It ensures accessibility for multiple entities while maintaining a seamless integration between services, all achieved through the creation of a data lake.
A data lake serves as a unified and centralized repository enabling organizations to store both structured and unstructured data at scale. In the cloud computing environment, particularly with AWS, a modern data lake architecture focuses on scalable and cost-effective service solutions to accommodate extensive datasets.This architecture not only facilitates the storage of vast amounts of data, but also supports detailed data insights. This includes features such as data pattern detection, mitigation of data anomalies, and the identification of intricate data relationships.
Components of a modern Data Lake architecture in AWS
Establishing and developing data lakes in the present requires considerable manual effort and consumes a significant amount of time. Following a modern data lake strategy, we abstract several key layers: data collection, data storage, data processing, and data visualization (see Figure 1).
The intention behind this strategy is to automate these processes, constructing a data lake that is both adaptable and tailored to our specific needs while ensuring flexibility, security, and scalability to support multiple use cases including AI and ML capabilities.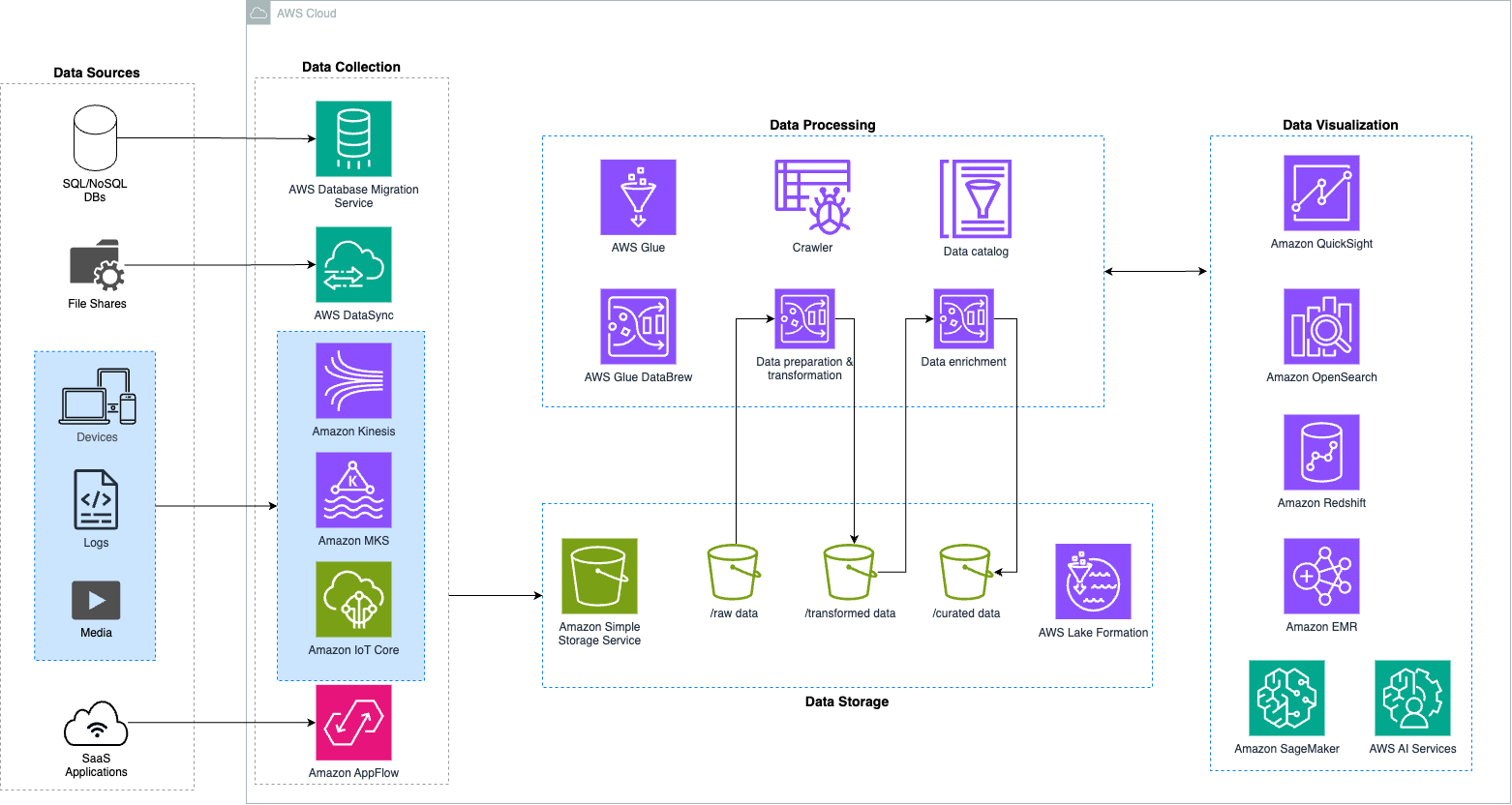
Figure 1.- AWS Data Lake Reference architecture
Starting with the data collection layer, our modern data lake architecture recognizes that a one-size-fits-all approach is insufficient to meet current industry requirements. Given that customers employ a diverse array of applications, in-house services, and technologies that generate data in various formats and from multiple sources, it becomes imperative to consolidate all generated data into a unified storage unit. This consolidation allows for the exploration and retrieval of data insights at the point of impact, thereby enhancing the decision-making process and fostering innovation.
Key components and main contributors to this layer include services such as AWS Glue to import vast amounts of data in real-time or batch into our cloud environment. Amazon Kinesis and Amazon MSK for scalable and robust streaming and real-time data ingestion. Additionally, the inclusion of AWS Database Migration Service facilitates the migration of on-premises databases and analytics workloads to AWS. Furthermore, AWS Data Sync can be used for transferring file data between on-premises and AWS Storage services.
Moving on to the next layer within our modern data lake architecture: data storage. In the AWS environment, Amazon S3 is utilized as the primary storage solution, chosen for its ability to store both structured and unstructured data without requiring additional processing, an advantageous feature, especially when the future use of the data is uncertain. Examples of such data include social media content, IoT device data, and nonrelational data from mobile apps.
Utilizing Amazon S3 as its foundation, AWS Lake Formation facilitates centralized governance, security, and global data sharing for analytics and machine learning. Through Lake Formation, you gain the capability to oversee fine-grained access control for both your data lake data stored on Amazon S3 and its corresponding metadata within the data catalog.
It is important to note that additional services tailored for transactional data, such as Amazon Redshift (a fully managed data warehousing service provided by AWS), can seamlessly integrate into the data lake solution. The integration choice depends on the specific use case and business requirements. For example, a portion of the refined data can be transferred to the data warehouse for storage of highly structured and quality data. This refined data is then utilized by business teams for conventional analytics and reports. Meanwhile, the data lake serves as the foundation for advanced analytics, such as machine learning. Additionally, there exists the potential for the refined data, after processing in the data warehouse, to be reintegrated into the data lake for inclusion in advanced analytics.
- In the processing layer of our architecture, we handle two primary functions: Constructing multi-step data processing pipelines,
- Orchestrating these pipelines based on events.
AWS Glue and AWS Step Functions serve as integral, serverless components for developing, organizing, and executing scalable data pipelines capable of handling substantial data volumes. This multi-step workflow undertakes tasks such as cataloging, validating, cleaning, transforming, and enriching datasets, facilitating their transition from raw to cleaned and curated zones within the storage layer.
To streamline this process, AWS Glue automates code generation, accelerating data transformation and loading processes. Additionally, it facilitates the execution of crawlers, which explore data lake folders to discover datasets, infer schema, and define tables in the data catalog. For simplified data cleaning and normalization, AWS Glue provides AWS Glue DataBrew, a visual data preparation tool that enables an interactive, code-free, point-and-click approach.
AWS Step Functions, acting as a serverless engine, aids in designing and orchestrating scheduled or event-driven data processing workflows. It establishes checkpoints and automatic restarts to ensure the consistency of data pipelines.
The data visualization layer includes analytical services, purpose-built applications, and entities that consume curated and enriched data based on established permissions. Its primary objective is to offer users efficient and meaningful methods to extract insights, make data-driven decisions, and perform analytics and machine learning processes using the data stored within the AWS data lake.
Key services within the AWS data lake consumption layer include:
- Amazon Athena: A serverless ad-hoc query service that empowers users to explore and analyze data, identifying patterns and insights through standard SQL. Compute engines like EMR and Athena can execute analytics workloads against your S3 data lake using the Glue Data Catalog by default.
- Amazon Redshift: Utilizes the data lake design to unload data from Amazon Redshift into the data lake, enabling data democratization. This fosters data sharing and collaboration among different teams within the company, enabling access, analysis, and the generation of new insights.
- Amazon QuickSight: A serverless BI tool facilitating the creation of dashboards, reports, and visualizations. It includes ML insights for potential fraud detection or anomaly identification, providing actionable insights.
- Amazon SageMaker: Provides a platform for the creation, training, and deployment of machine learning models, conducting advanced analytics that consumes curated data directly from the data lake.
Conclusion
In this article, we have presented a comprehensive guide to AWS Data Lakes, navigating the dynamic landscape of data management. The increasing adoption of data lakes by organizations aiming to store, manage, and analyze extensive and diverse datasets is evident. The primary focus is on the cloud environment, with Amazon Web Services (AWS) playing a central role in delivering robust solutions for modern data lake architectures.
This guide systematically reveals the layers of a modern data lake architecture on AWS, covering aspects from data collection to visualization. It underscores the importance of automation across these layers to create adaptable and customized data lakes, ensuring flexibility, security, and scalability for various use cases, including advanced functionalities such as AI and ML.
Key components were introduced, and we took a closer look at the crucial role of each layer in the big picture. Amazon S3 is prominently featured in the data storage layer, providing scalability and versatility for both structured and unstructured data. Emphasis is placed on AWS Lake Formation, ensuring centralized governance, security, and global data sharing to enforce fine-grained access control, fostering collaboration and innovation across diverse teams.
The processing layer introduces AWS Glue and AWS Step Functions, streamlining data processing pipelines efficiently and automating tasks to expedite transformation processes. The data visualization layer emerges as the interface for users and applications, offering efficient means to extract insights, make data-driven decisions, and execute analytics and machine learning.
In summary, AWS Data Lakes, with their modern architectures and an extensive suite of AWS services, present an encompassing ecosystem for organizations navigating the intricacies of data management in the cloud. By embracing these solutions, businesses can unleash the full potential of their data, improving the decision-making process and promoting innovation in the ever-evolving realm of data management.