

The Problem
As a digital publishing house, Axel Springer needs to maintain accountability for the thousands of images that are published on its online platforms. This involves purchasing the rights for usage of certain images, maintaining a track of where the images were used and for how long can they continue to stay online. In order to support this, they built an internal SaaS application for aggregating purchase information related to the various images with their various online platforms as individual tenants. The application acts as a central repository for information corresponding to the metadata of an image like the title, caption, price, the duration of purchase, articles the image is used on etc., which vendors submit to a third party system that is in turn synced with the application to keep it up to date.
The accounting department then utilizes the application to generate invoices for the usage of the images. Users, however, were facing a few issues in certain functionalities of the application:
In order to synchronize the metadata of an image with the third party system for changes in prices or other details, application users had to select an individual image and perform an update. Keeping track of thousands of images becomes difficult in this scenario, as each individual image had to be selected and sent for update of metadata processing.
In order to create an invoice for a vendor, a vendor had to be selected individually. Its images were added to the invoice individually and then sent for invoice creation. During the process, the user couldn’t perform any other tasks on the application either.
Overall, the application was suffering from bad user experience and kreuzwerker stepped in to support.
The Solution
CQRS
CQRS allows you to separate the load from reads and writes enabling you to scale each independently. In case your application has a disparity between reads and writes this is very handy. The biggest rationale for the usage of this software pattern is that in more complicated domains, having the same conceptual model for commands and queries, leads to a more complex model that doesn’t work well in the long run.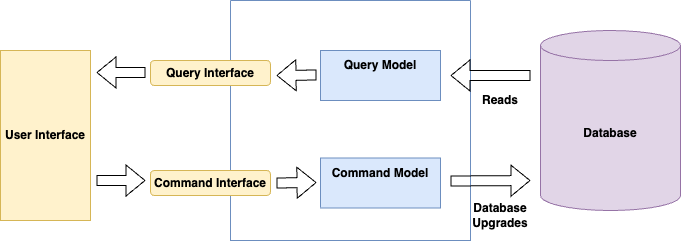
Diagram 1: Command and Query Separation
As seen in Diagram 1, CQRS uses a separate model for all queries. Once this has been achieved, the pattern can then further be expanded (as visualized in Diagram 2) to use different database technologies for reading and writing with eventual consistency achieved between the read and write model using events via an event bus or queue. With a reporting database in place, you will use a main database system for all write queries and offload the read queries to the reporting database.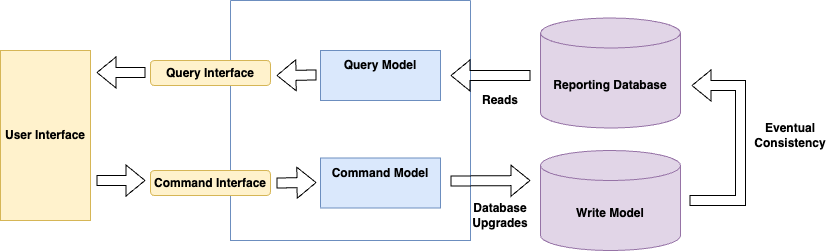
Diagram 2: CQRS Pattern
Implementation
The application’s architecture already follows the patterns of CQRS which can be seen highlighted in Diagram 3 below. The application uses DynamoDB as an event store to allow for event sourcing and to handle all the write requests. As this database makes all the changes to the data, it acts as a source of truth for all data in the system in the form of events. The application further utilizes Aurora MySQL Serverless, which acts as a read model. This read model is utilized for reading the current state of the system and all the read queries are directed towards it.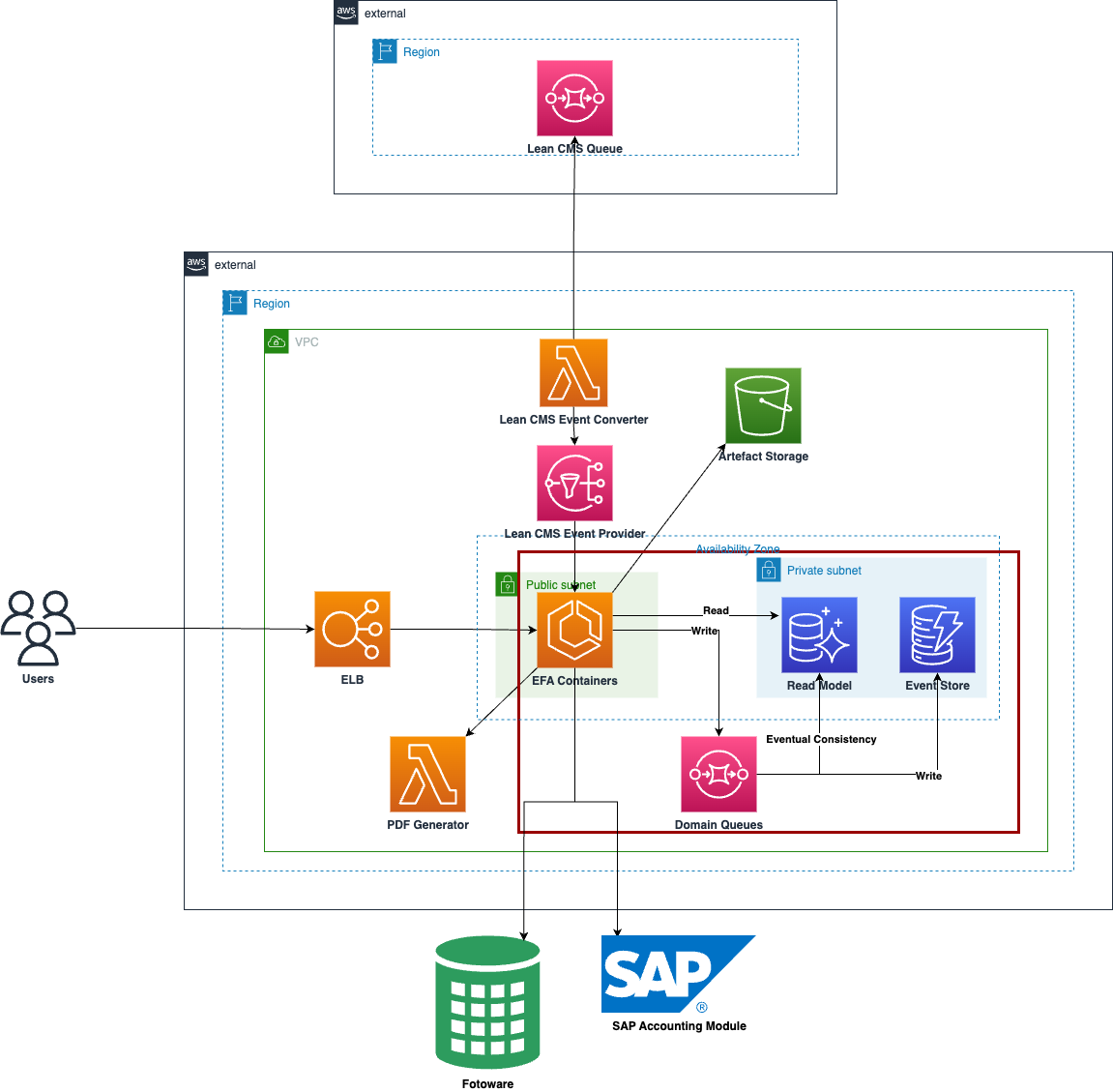
Diagram 3: AWS Architecture Diagram
In true kreuzwerker’s motto of touching running systems, we utilized the existent infrastructure and code base to build wrappers on top of the metadata update and invoice generation. This allowed users to now select multiple images and trigger batch processing for the updates OR select multiple vendors and trigger batch processing for the invoice generation. Using the principle of CQRS, we now generate a command that in turn would generate individual events for each image to be updated/invoice to be generated. These updates would be pushed to an SQS queue for first updating the event store/write model with the latest metadata/generated invoice data, and later fan out more events that would update the read model/view with the updated data/generated artefacts. The separation between reads and writes, and the eventually consistent mode of working, allowed for asynchronous processing of requests. This further enabled users to continue working on the other tasks within the application without blocking the I/O for all images to be updated/all invoices to be generated. APIs were provided to submit these commands and to view the status of a batch job in order to ensure observability of the current status of the job in the system. In addition, storing an individual event in the event store for each image/vendor allowed for the possibility of replaying the event to perform operations instead of generating new commands each time.
The Result
With the help of kreuzwerker, Axel Springer now has a user friendly application, which reduces the number of clicks required to update the metadata of thousands images. Users no longer need to select an individual image to update it’s metadata and with one click can queue the updating of all the images. For the generation of the credit advices, the users no longer have to wait while the application generates a credit advice to perform more tasks. They can again queue the generation of these credit advices on a per vendor basis asynchronously.
Summary
In this post, we presented a use case for CQRS in a live production grade application to trigger batch processing. Usually considered a very complex pattern to implement, having it in your toolbox can definitely help solve performance related issues. If you found this article useful, do share it with your friends. If you have more software patterns that you would like us to explore, please let us know. We’d be happy to share our learnings on production grade applications.
Thank you for reading!